Access Data on a CAPS Server¶
A range of tools is available to access data and information on a CAPS server.
Name |
SW Package |
Description |
|---|---|---|
caps-tools |
A command-line tool for retrieving data and meta information from a CAPS server |
|
caps-tools |
A command-line tool for data inspection and extraction from individual CAPS data files (RIFF), e.g., in a CAPS archive |
|
caps-tools |
A virtual overlay file system presenting a CAPS archive directory as a read-only SDS archive with no extra disk space requirement. |
|
seiscomp |
The plugin fetches miniSEED and RAW data from a CAPS server and provides the data to seedlink |
|
seiscomp |
The RecordStream implementations for CAPS |
|
caps-plugins |
Automatic or interactive synchronization of two CAPS servers |
|
caps-server |
The web interface provided by the CAPS server |
|
caps-server |
FDSNWS dataselect interface provided by the CAPS server |
|
caps-server |
Winston Waveform Server interface provided by the CAPS server |
|
seiscomp |
A command-line tool for generating availability information from CAPS archive |
RecordStream: caps/capss¶
SeisComP applications access waveform data through the RecordStream interface. To fetch data from a CAPS server specific RecordStream implementations may be used:
caps: regular RecordStream implementation to access the CAPS server,
capss: RecordStream implementation to access the CAPS server secured by SSL, user name and password. Similar to https, capss will establish a Secure Socket Layer (SSL) communication.
Configuration¶
In order to make use of the caps or the capss RecordStream configure the
RecordStream URL in recordstream. Let it point to the CAPS server
providing the data. Examples for caps and capss:
recordstream = caps://server:18002
recordstream = capss://foo:bar@server:18022
Optional parameters are available for caps/capss.
Note
While the caps/capss RecordStream provides data in real time
and from archive, some modules, e.g., scart [14], fdsnws [11] or
GIS [5] should be strictly limited to reading from archive only by
the option arch:
recordstream = caps://server:18002?arch
recordstream = capss://foo:bar@server:18022?arch
Otherwise requests attempting to fetch missing data may hang forever.
Optional Parameters¶
Optional RecordStream parameters which can be combined:
arch- read from CAPS archive only,ooo- out of order, data are fetched and provided in the order of their arrival in the CAPS server, useful for analysing if data have arrived out of order,pass- password if server requires authentication,request-file- file specifying the streams to be requested. One stream per line. Per line: net sta loc stream startTime endTime,timeout- timeout of acquisition in seconds. Data acquisition will be restarted,user- user name if server requires authentication.
URL |
Description |
|---|---|
caps://server:18002?arch |
Read data from CAPS archive. Stop data acquisition when all available waveforms are fetched. |
caps://server:18002?ooo |
Fetch data in the original order of arrival. |
caps://server:18002?request-file=request.txt |
Request only streams in time intervals given in request.txt |
caps://server:18002?timeout=5 |
Apply a timeout of 5 seconds. |
capss://server:18022?user=foo&pass=bar |
Use secure protocol (SSL) with user name and password. Read the section on Authentication by user name and password (shadow.cfg) for details on the generation of user names and passwords. |
Combination with other RecordStream interfaces¶
The caps and the capss RecordStream may be combined with other RecordStream interfaces.
Examples:
Decimation
Use the decimation RecordStream [6] interface to fetch data from a CAPS server running on localhost decimated to 1 sample per second.
global configuration:
recordstream = dec://caps/localhost:18002?rate=1
command line parameter:
-I dec://caps/localhost:18002?rate=1
Resample
Use the resample RecordStream [6] interface to fetch data from a CAPS server running on localhost resampled to 16 samples per second.
global configuration:
recordstream = resample://caps/localhost:18002?rate=16
command line parameter:
-I resample://caps/localhost:18002?rate=16
CAPS command-line interface (CLI) client: capstool¶
capstool is a CAPS client application for retrieving data and listing available streams from an operational CAPS server. The CAPS server may run locally or remotely as all communication is performed over the network (option:-H).
Data requests are based on time windows and stream IDs. The data is provided in
its origin format on stdout or, with -o as a single file. In
particular capstool may be used to fetch miniSEED data and create miniSEED
files.
capstool can also be used for testing the server as it provides information on available streams with
their time window (-Q, -I).
Finally, the option --purge allows deletion of data from the CAPS
archive. This feature however requires purge
permissions for the corresponding user.
Data file access: rifftool/capssds¶
The data files in the CAPS archive contain a small additional header describing the data format and implementing an index for fast and in-order data retrieval. Read the format documentation for more details. In contrast to miniSEED files in SDS archives created, e.g., by slarchive [20] or scart [14], the original miniSEED files stored in the CAPS archive cannot be directly read by common seismological applications.
You may access data files directly:
Test and retrieve data files using rifftool. rifftool addresses individual files directly and does not require the CAPS server to be running.
Run capssds to create a virtual overlay file system presenting a CAPS archive directory as a read-only SDS archive with no extra disk space requirement. The CAPS archive directory and file names are mapped. An application reading from a file will only see miniSEED records ordered by record start time. You may connect to the virtual SDS archive using the RecordStream SDS or directly read the single miniSEED file. Other seismological software such as ObsPy or Seisan may read directly from the SDS archive of the files therein.
Synchronize with another CAPS server: caps2caps¶
Use caps2caps to synchronize your CAPS server with another one. You may push or pull data on either side. In contrast to the generation of regular SDS archives, e.g., by scart, the CAPS server will not generate duplicate data records if executing caps2caps multiple times. While synchronizing observe the web interface for the statistics of received, written or rejected data packages.
Connect from SeedLink: caps_plugin¶
The caps_plugin plugin fetches data from a CAPS server and provides the data to seedlink. The plugin can be configured and started as any other plugin for seedlink or executed on demand. Select caps when choosing the plugin in the seedlink binding configuration.
Examples:
Fetch data from a remote CAPS server and make them available in your seedlink instance:
configure the caps_plugin plugin in the bindings configuration of your seedlink instance pointing to the remote CAPS server
enable and start seedlink
seiscomp enable seedlink seiscomp start seedlink
Provide data from a CAPS server by seedlink on the same machine to external clients:
create another seedlink instance, e.g., seedlinkP:
seiscomp alias create seedlinkP seedlink
configure the caps_plugin in the bindings configuration of seedlinkP pointing to the local CAPS server.
enable and start seedlinkP:
seiscomp enable seedlinkP seiscomp start seedlinkP
Web interface¶
The CAPS server ships with a web interface. Beside allowing you to view server statistics, data stored stored on the server can be downloaded for any time if the original format is miniSEED.
For downloading miniSEED data
Select the stream(s) of interest.
Zoom in to the period of interest. Zooming in and out in time works by right-mouse button actions just like in other SeisComP GUI applications like scrttv [17].
Click on the download button to download the miniSEED file. An error message will be printed in case the original format is not miniSEED.
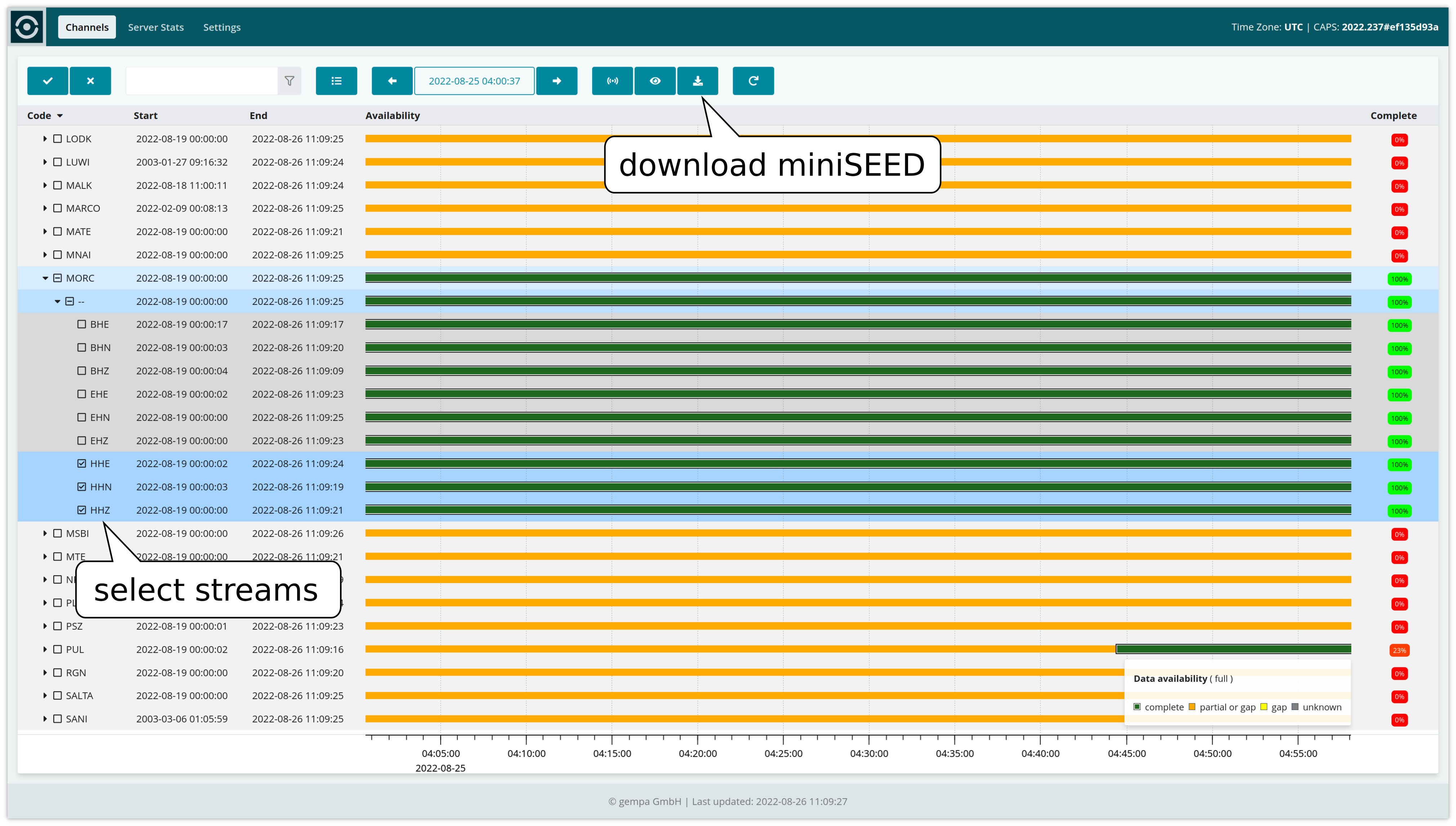
Stream perspective of CAPS Web interface allowing to download miniSEED data for selected streams.¶
Built-in FDSNWS¶
CAPS speaks natively FDSN Web Services, FDSNWS [1] providing
waveform data via dataselect. Information on events and stations are not
delivered. The waveform data will be delivered through the port configured in
AS.http.port or the port configured by a reverse proxy server such as
NGINX. Contact your system administrator for information on the reverse proxy
server. Read the documentation of the CAPS server for
the configuration.
Built-in WebDAV¶
CAPS provides a WebDAV service allowing you to access data files over the
network though a WebDAV client. Currently the only available endpoint is
/dav/sds presenting the CAPS archive directory as a read-only SDS
archive with no extra disk space requirement.
The CAPS archive directory and file names are mapped. An application reading from a file will only see miniSEED records ordered by record start time. Unless configured otherwise the reported file size in a directory listing only accounts for the miniSEED records.
The service is available through the port configured
in AS.http.port or the port configured by a reverse proxy server such
as NGINX. If a reverse proxy is used and CAPS is put on a subpath the
AS.http.rootURL must be configured accordingly.
Clients¶
The following WebDAV clients have been tested so far:
Nautilus on Gnome: Use
dav://HOST:PORT/dav/sdsDolphine on KDE: Use
davfs://HOST:PORT/dav/sdsDAVx5 on Android:
Options -> Tools -> WebDAVdavfs2 user space filesystem on Linux
To mount a WebDAV resource via davfs2 several options exist:
davfs2 - command-line¶
mount -t davfs http(s)://address:<port>/dav/sds /tmp/sds
davfs2 - /etc/fstab¶
http(s)://address:<port>/dav/sds /tmp/sds davfs ro,user,uid=username,noauto 0 0
Performance optimization¶
To obtain the mapped SDS file size the CAPS data file must be scanned for
miniSEED records. Although only the header data is read this is still an
expensive operation for hundreds of files. A file size cache is used containing
up to AS.http.DAC.SDS.cachedFileSizes entries each consuming 56 bytes
of memory. File sizes recently accessed are pushed to the front of the cache. A
cache item is invalidated if the modification time of the CAPS data file is more
recent than the entry creation time.
If your use case does not require the listing of the exact file size, you may
use the AS.http.DAC.SDS.sloppySize option which will stop generating
the miniSEED file size and will return the size of the CAPS file
instead.
Built-in Winston waveform server¶
CAPS speeks natively Winston Waveform Server protocol, WWS, [9], e.g., to SWARM [7] by USGS. Read the documentation of the CAPS server for the configuration.
Data availability information¶
Web interface¶
The Channels perspective of the CAPS web interface indicates periods of availability and of gaps on level of network, station, sensor location and channel. The resolution of colors and percentages is linked to the granularity of the data detection which increases with shorter time windows in order to optimize the speed of the calculation.
capstool¶
The CAPS server stores information on received data segments including their start and end times. Information on resulting gaps can be retrieved by capstool. Examples (both are equivalent):
echo "2023,05,01,12,00,00 2023,05,03,00,00,00 NET * * *" | capstool -G --tolerance=0.5 -H localhost
echo "2023-05-01T12 2023-05-03 NET * * *" | capstool -G --tolerance=0.5 -H localhost
scardac¶
The availability of data in the caps archive can be analyzed and written to the
SeisComP database by the SeisComP module scardac [13]. For availability analysis
add the plugin daccaps to the list of plugins and URL of the caps
archive to the archive configuration of scardac [13]. The daccaps plugin
ships with the gempa package caps-server.
Example configuration of scardac [13] (scardac.cfg):
plugins = ${plugins}, daccaps
archive = caps:///home/data/archive/caps/
Example call:
scardac --plugins="daccaps, dbmysql" -d localhost -a caps:///home/data/archive/caps/ --debug
Note
As of SeisComP in version 6, scardac has received significant optimization. Instead of scanning the full archive, only files which have changed since the last scan will be examined. This means that when scanning the entire archive, the first run may be more time consuming than subsequent ones when executed within reasonable intervals.
The data availability information can be retrieved from the database, e.g., using fdsnws [11] or scxmldump [18].