Data Management¶
CAPS uses the SDS directory structure for its archives shown in figure 5. SDS organizes the data in directories by year, network, station and channel. This tree structure eases archiving of data. One complete year may be moved to an external storage, e.g. a tape library.
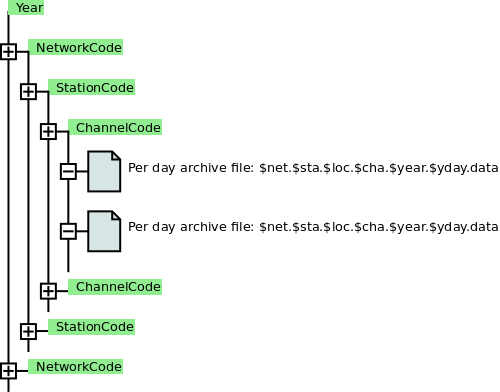
SDS archive structure of a CAPS archive¶
The data are stored in the channel directories. One file is created per sensor
location for each day of the year. File names take the form
$net.$sta.$loc.$cha.$year.$yday.data with
net: network code, e.g. ‘II’
sta: station code, e.g. ‘BFO’
loc: sensor location code, e.g. ‘00’. Empty codes are supported
cha: channel code, e.g. ‘BHZ’
year: calender year, e.g. ‘2021’
yday: day of the year starting with ‘000’ on 1 January
Note
In contrast to CAPS archives, in SDS archives created with slarchive the first day of the year, 1 January, is referred to by index ‘001’.
File Format¶
CAPS uses the RIFF file format
for data storage. A RIFF file consists of chunks. Each chunk starts with a 8
byte chunk header followed by data. The first 4 bytes denote the chunk type, the
next 4 bytes the length of the following data block. Currently the following
chunk types are supported:
SID - stream ID header
HEAD - data information header
DATA - data block
BPT - b-tree index page
META - meta chunk of the entire file containing states and a checksum
Figure 6 shows the possible structure of an archive file consisting of the different chunk types.

Possible structure of an archive file¶
SID Chunk¶
A data file may start with a SID chunk which defines the stream id of the data that follows in DATA chunks. In the absence of a SID chunk, the stream ID is retrieved from the file name.
content |
type |
bytes |
|---|---|---|
id=”SID” |
char[4] |
4 |
chunkSize |
int32 |
4 |
networkCode + ‘\0’ |
char* |
len(networkCode) + 1 |
stationCode + ‘\0’ |
char* |
len(stationCode) + 1 |
locationCode + ‘\0’ |
char* |
len(locationCode) + 1 |
channelCode + ‘\0’ |
char* |
len(channelCode) + 1 |
HEAD Chunk¶
The HEAD chunk contains information about subsequent DATA chunks. It has a fixed size of 15 bytes and is inserted under the following conditions:
before the first data chunk (beginning of file)
packet type changed
unit of measurement changed
content |
type |
bytes |
|---|---|---|
id=”HEAD” |
char[4] |
4 |
chunkSize (=7) |
int32 |
4 |
version |
int16 |
2 |
packetType |
char |
1 |
unitOfMeasurement |
char[4] |
4 |
The packetType entry refers to one of the supported types described in
section Packet Types.
DATA Chunk¶
The DATA chunk contains the actually payload, which may be further structured into header and data parts.
content |
type |
bytes |
|---|---|---|
id=”DATA” |
char[4] |
4 |
chunkSize |
int32 |
4 |
data |
char* |
chunkSize |
Section Packet Types describes the currently supported packet types.
Each packet type defines its own data structure. Nevertheless CAPS
requires each type to supply a startTime and endTime information for
each record in order to create seamless data streams. The endTime may be
stored explicitly or may be derived from startTime, chunkSize,
dataType and samplingFrequency.
In contrast to a data streams, CAPS also supports storing of individual measurements. These measurements are indicated by setting the sampling frequency to 1/0.
BPT Chunk¶
BPT chunks hold information about the file index. All data records are indexed using a B+ tree. The index key is the tuple of start time and end time of each data chunk to allow very fast time window lookup and to minimize disc accesses. The value is a structure and holds the following information:
File position of the format header
File position of the record data
Timestamp of record reception
This chunk holds a single index tree page with a fixed size of 4kb (4096 byte). More information about B+ trees can be found at https://en.wikipedia.org/wiki/B%2B_tree.
META Chunk¶
Each data file contains a META chunk which holds information about the state of the file. The META chunk is always at the end of the file at a fixed position. Because CAPS supports pre-allocation of file sizes without native file system support to minimize disc fragmentation it contains information such as:
effectively used bytes in the file (virtual file size)
position of the index root node
the number of records in the file
the covered time span
and some other internal information.
Optimization¶
After a plugin packet is received and before it is written to disk, CAPS tries to optimize the file data in order reduce the overall data size and to increase the access time. This includes:
merging data chunks for continuous data blocks
splitting data chunks on the date limit
trimming overlapped data
Merging of Data Chunks¶
CAPS tries to create large continues blocks of data by reducing the number of data chunks. The advantage of large chunks is that less disk space is occupied by data chunk headers. Also seeking to a particular time stamp is faster because less data chunk headers need to be read.
Data chunks can be merged if the following conditions apply:
merging is supported by packet type
previous data header is compatible according to packet specification, e.g.
samplingFrequencyanddataTypematchesendTimeof last record equalsstartTimeof new record (no gap)
Figure 7 shows the arrival of a new plugin packet. In alternative A) the merge failed and a new data chunk is created. In alternative B) the merger succeeds. In the latter case the new data is appended to the existing data block and the original chunk header is updated to reflect the new chunk size.
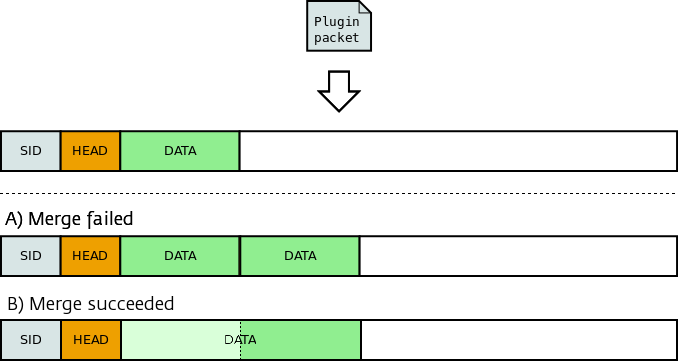
Merging of data chunks for seamless streams¶
Splitting of Data Chunks¶
Figure 8 shows the arrival of a plugin packet containing data of 2 different days. If possible, the data is split on the date limit. The first part is appended to the existing data file. For the second part a new day file is created, containing a new header and data chunk. This approach ensures that a sample is stored in the correct data file and thus increases the access time.
Splitting of data chunks is only supported for packet types providing the
trim operation.
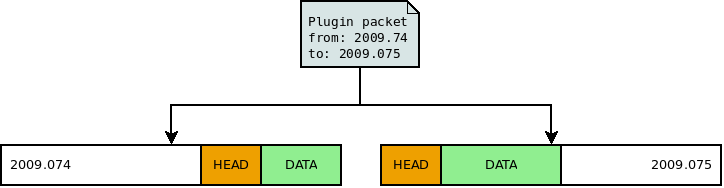
Splitting of data chunks on the date limit¶
Trimming of Overlaps¶
The received plugin packets may contain overlapping time spans. If supported by the packet type CAPS will trim the data to create seamless data streams.
Packet Types¶
CAPS currently supports the following packet types:
RAW - generic time series data
ANY - any possible content
MiniSeed - native MiniSeed
RAW¶
The RAW format is a lightweight format for uncompressed time series data with a minimal header. The chunk header is followed by a 16 byte data header:
content |
type |
bytes |
|---|---|---|
dataType |
char |
1 |
startTime |
TimeStamp |
[11] |
year |
int16 |
2 |
yDay |
uint16 |
2 |
hour |
uint8 |
1 |
minute |
uint8 |
1 |
second |
uint8 |
1 |
usec |
int32 |
4 |
samplingFrequencyNumerator |
uint16 |
2 |
samplingFrequencyDenominator |
uint16 |
2 |
The number of samples is calculated by the remaining chunkSize divided by
the size of the dataType. The following data types value are supported:
id |
type |
bytes |
|---|---|---|
1 |
double |
8 |
2 |
float |
4 |
100 |
int64 |
8 |
101 |
int32 |
4 |
102 |
int16 |
2 |
103 |
int8 |
1 |
The RAW format supports the trim and merge operation.
ANY¶
The ANY format was developed to store any possible content in CAPS. The chunk header is followed by a 31 byte data header:
content |
type |
bytes |
|---|---|---|
type |
char[4] |
4 |
dataType (=103, unused) |
char |
1 |
startTime |
TimeStamp |
[11] |
year |
int16 |
2 |
yDay |
uint16 |
2 |
hour |
uint8 |
1 |
minute |
uint8 |
1 |
second |
uint8 |
1 |
usec |
int32 |
4 |
samplingFrequencyNumerator |
uint16 |
2 |
samplingFrequencyDenominator |
uint16 |
2 |
endTime |
TimeStamp |
11 |
The ANY data header extends the RAW data header by a 4 character type
field. This field is indented to give a hint on the stored data. E.g. an image
from a Web cam could be announced by the string JPEG.
Since the ANY format removes the restriction to a particular data type, the
endTime can no longer be derived from the startTime and
samplingFrequency. Consequently the endTime is explicitly specified in
the header.
Because the content of the ANY format is unspecified it neither supports the
trim nor the merge operation.
MiniSeed¶
MiniSeed is the standard for the exchange of seismic time series. It uses a fixed record length and applies data compression.
CAPS adds no additional header to the MiniSeed data. The MiniSeed record is directly stored after the 8-byte data chunk header. All meta information needed by CAPS is extracted from the MiniSeed header. The advantage of this native MiniSeed support is that existing plugin and client code may be reused. Also the transfer and storage volume is minimized.
Because of the fixed record size requirement neither the trim nor the
merge operation is supported.