Multi-Event Relocation
Multi-event relocation is used to relocate an event catalog in offline mode. There is no interaction with running SeisComP modules, and nothing is written to the database, although results can optionally be imported later.
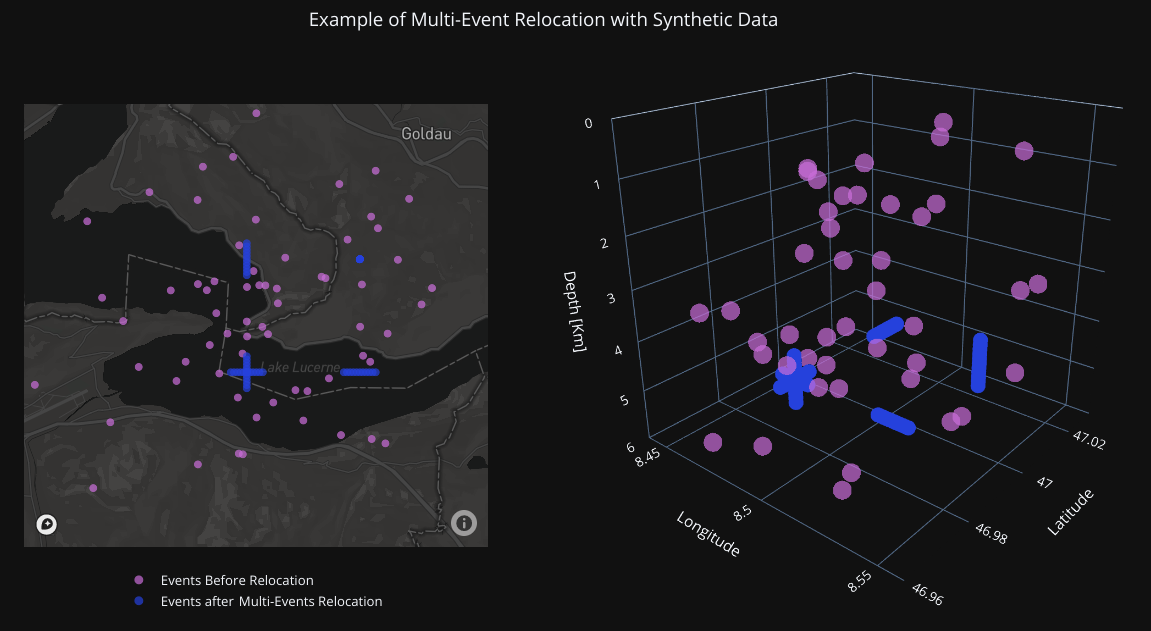
Relocation test using synthetic data. Events from four clusters had their locations and times altered to simulate errors. The multi-event double-difference inversion was then applied, successfully recovering the original locations and times.
Summary
Create a
scrtddprofile (e.g., using thescconfigGUI) to define relocation settings.Use the
sclistorgcommand to select an event catalog from a SeisComP database, or create an input catalog manually (event.csv,phase.csv, andstations.csv).Use the
scrtdd --reloc-catalogoption to relocate the events.Utilize the relocation output (
reloc-event.csv,reloc-phase.csv, andreloc-stations.csv, or the SCML filerelocated.xml) as needed.
For a practical example, refer to the multi-event.sh script in this folder.
Getting Started
Create a scrtdd profile (e.g., via scconfig) to define the relocation settings. While the default configuration provides a good starting point, you may need to iterate to find optimal settings for your specific dataset. You must also configure a velocity model (see Custom Velocity Models).

The input catalog for relocation can be provided in three formats:
A list of origin IDs stored in a SeisComP database.
A triplet of CSV files:
station.csv,event.csv, andphase.csv.A file in SCML format.
Event Catalog: List of Origin IDs
This format consists of a text file containing the SeisComP origin IDs to be relocated. scrtdd uses these IDs to fetch all necessary metadata from the SeisComP database.
Example myCatalog.csv (a mandatory column named origin is required; other columns are ignored):
origin
Origin/20181214107387.056851.253104
Origin/20180053105627.031726.697885
Origin/20190121103332.075405.6234534
Origin/20190223103327.031726.346363
[...]
The sclistorg tool, installed alongside scrtdd, is used to list origin IDs satisfying specific criteria such as time period, geographic area, author, or agency. See sclistorg --help for a full list of options:
# List preferred origin IDs for all events between 2018-11-27 and 2018-12-14
sclistorg --begin "2018-11-27 00:00:00" --end "2018-12-14 00:00:00" \
--org-type preferred [db options]
# Filter by event type and specific agencies
sclistorg --begin "2018-11-27 00:00:00" --end "2018-12-14 00:00:00" \
--org-type preferred --ev-type "earthquake,quarry blast" \
--inc-agency Agency1,Agency2 [db options] > myCatalog.csv
sclistorg output (in the example myCatalog.csv) can be used directly as the input catalog for scrtdd to relocate:
scrtdd --reloc-catalog myCatalog.csv --profile myProfile \
--dump-diagnostics --verbosity=3 --console=1 [db options]
The output consists of three files (reloc-event.csv, reloc-phase.csv, and reloc-stations.csv) containing the relocated catalog. The --xmlout option can be used to generate a SeisComP XML file in the standard output containing the relocated origins in XML format.
Using --dump-diagnostics generates a folder containing diagnostic information (initial/final-double-difference.csv), cluster details (pair.csv) and cross-correlation results (xcorr.csv). pair.csv can be reused in subsequent relocations using the --clusters to skip the clustering phase. Similarly, xcorr.csv can be reused with the --xcorr option to skip the cross-correlation on already processed pais.
Note that the output CSV files can serve as input for another relocation. For example, an initial relocation might use the ellipsoid algorithm and relaxed minimum station-to-event-pair-distance ratio constraint to accommodate large errors in initial locations, followed by a second pass using a nearest-neighbor approach and cross-correlation for higher precision.
Please note that a database connection is required for both scrtdd and sclistorg. This can be configured in global.cfg or passed via the command line using -d mysql://user:password@host/seiscompDbName.
Event Catalog: Plain CSV Files
This format contains complete origin information, eliminating the need for database access during relocation. These files can be generated from an existing list of origin IDs:
scrtdd --dump-catalog myCatalog.csv --verbosity=3 --console=1 [db options]
This command generates event.csv, phase.csv, and stations.csv. This format also allows for the relocation of events not currently stored in a SeisComP database.
To relocate using the CSV triplet:
scrtdd --reloc-catalog station.csv,event.csv,phase.csv --profile myProfile \
--dump-diagnostics --verbosity=3 --console=1 [db options for cross-correlation]
While this format does not require a database for origin information, a database or inventory file must be provided if cross-correlation is enabled to retrieve stream orientation (e.g., vertical vs. horizontal components).
File structure details:
event.csv:
id,isotime,latitude,longitude,depth,magnitude
1,2019-11-05T00:54:21.256705Z,46.318264,7.365509,4.7881,3.32
2,2019-11-05T01:03:06.484287Z,46.320718,7.365435,4.2041,0.64
3,2019-11-05T01:06:27.140654Z,46.325626,7.356148,3.9756,0.84
4,2019-11-05T01:12:25.753816Z,46.325012,7.353627,3.7090,0.39
depthis in km.magnitudecolumn is currently not used, omit the column if the values are unknown.
station.csv:
latitude,longitude,elevation,networkCode,stationCode,locationCode
45.980278,7.670195,3463.0,4D,MH36,A
45.978720,7.663000,4003.0,4D,MH48,A
46.585719,8.383171,2320.4,4D,RA43,
45.903349,6.885881,2250.0,8D,AMIDI,00
46.371345,6.873937,379.0,8D,NVL3,
elevationis in meter
phase.csv:
eventId,isotime,lowerUncertainty,upperUncertainty,type,networkCode,stationCode,locationCode,channelCode
1,2019-11-05T00:54:22.64478Z,0.025,0.025,Pg,8D,RAW2,,HHZ
1,2019-11-05T00:54:23.58254Z,0.100,0.100,Sg,8D,RAW2,,HHT
1,2019-11-05T00:54:22.7681Z,0.025,0.025,Pg,CH,SAYF2,,HGZ
1,2019-11-05T00:54:24.007619Z,0.050,0.050,Sg,CH,STSW2,,HGT
2,2019-11-05T01:03:08.867835Z,0.050,0.050,S,8D,RAW2,,HHT
2,2019-11-05T01:03:07.977432Z,0.025,0.025,P,CH,SAYF2,,HGZ
2,2019-11-05T01:03:08.9947Z,0.050,0.050,Sg,CH,SAYF2,,HGT
2,2019-11-05T01:03:09.12808Z,0.050,0.050,P,CH,STSW2,,HG1
2,2019-11-05T01:03:09.409276Z,0.025,0.025,Sg,CH,SENIN,,HHT
lowerUncertaintyandupperUncertaintyare in seconds and optional and used only whenusePickUncertaintiesis enabled in the solver. Omit these columns, or leave blank, if the uncertainties are unknown.channelCode: used only in the cross-correlation and specifies the waveform to fetch for a phase.
Event Catalog: XML/SCML File
This is a variation of the origin ID relocation where the data is read from an events.xml file instead of a database:
# events.xml contais the origins data
# myCatalog.csv contains the origin ids inside events.xml we want relocate
scrtdd --reloc-catalog myCatalog.csv --ep events.xml --profile myProfile \
--dump-diagnostics --verbosity=3 --console=1 [db options]
Relocation Process
From a high-level view, multi-event relocation in rtDD consists of several sequential steps:
Clustering: Independent event clusters are identified. Also, for each cluster, the phases to be used for each even pair are selected. The output of this phase is a double-difference system per cluster.
Differential time refinement: Differential times are optionally improved through cross-correlation (Cross-Correlation).
Inversion: The double-difference system is solved iteratively to determine the updated hypocenter locations.
Clustering
The clustering algorithm identifies groups of events that are connected based on user-defined criteria, such as maximum inter-event distance and a minimum number of common phases at the same stations. Events belong to the same cluster if they are directly connected or linked through a chain of connections. Each cluster is then relocated independently.
rtDD constructs and solves a double-difference system for each cluster, incorporating every event pair and the phases selected during the clustering stage. Events that do not meet the clustering criteria are not relocated.
Double-Difference System
In a cluster, every pair of events sharing common phases at a station contributes to the system of equations. While indirectly connected events have their relative locations constrained by the existing chain of connections, but they do not have dedicated equations in the system.
Thus, rtDD creates an equation for each phase k a pair of events i and j have at a common station. This is done for every event pair in a cluster. The equation is defined as:
(1)
One side of the equation contains the double-difference  and on the other side the partial derivatives
and on the other side the partial derivatives  and hypocenter changes
and hypocenter changes  (
( ) we want to compute for the two paired events i and j.
) we want to compute for the two paired events i and j.
The double-difference is defined as the difference between the observed and calculated differential travel times:
(2)
and t is the travel time for the phase k for the events i and j. The observed differential time can then be computed as the difference in phase travel times using the observed picks (pick time - event time) and optionally refined via cross-correlation (Cross-Correlation). The calculated travel time is the difference of the theoretical phase travel times computed using a velocity model.
The partial derivatives and hypocenter changes part of the equation (1) can be written in full as:

Following Waldhauser & Ellsworth (2000), the double-difference system is expressed in matrix form as:
(3)
where G defines a matrix of size M x 4N (M, number of double-difference equations; N, number of events) containing the partial derivatives, d is the data vector of size M containing the double-difference values, m is a vector of length 4N, ![[\Delta x, \Delta y, \Delta z, \Delta \tau]^T](data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAIwAAAAUBAMAAACt28gjAAAAMFBMVEX///8AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAv3aB7AAAAD3RSTlMAv8+LGOmvnd37SGB08zJgVNX9AAAACXBIWXMAAA7EAAAOxAGVKw4bAAABwElEQVQ4y6WUP0gCYRjGn/O0s/Mv0RwGEbQdFDhE4BIuga1RkOAaeElQQ5DQUC0htEnEbf0hUAgiKOhaHcShLQJpaCoKbA17v/tO/e5rMPIDkUef+/3e9+QEBj2B3H6ygRFjEIY6iVvsIosEBf+i9O28lOVCL/tg4AS2gxlqSZflpRHlQi/7gGiJ3hkmfSDJtkreD+RCLxNGLboYs+K1a7pklwu9TBifyTF+M+i1p+G1ywUhEyZicYwGx343djXqysBsl3E8uNPxgnKsW0KOrrbbJcJkwDFpMLtunxlPrgxk89tl7HWmc8ZL3myKWWnW2TTq1AzHbIDZNVRSfGMtxWwh/RNlfhkvoAlDzBbizlLg05AcAbZroXtrgCX6VRMEcqfjhTd4c1HEkBwhtvsKujLcG4hUtWJnOqcQsuDNWRHD5GQPRb9gdmTMlkkFze50bLw6LS5mxRYxaxd0dow59VFtRidomRrl0xZi+LDwQma3EC7MHooZw00R03ZO47V+XYN+BMSc/A01lwfO6a66hQX/c1XMeIeI8ZywGNbpZUuPm5T7Y5bp0f0vRmglFEOaDr9zf8z0Nv6OGfDfb5y//wAXpJULpIuimgAAAABJRU5ErkJggg==) , containing the changes in hypocentral parameters we wish to determine, and W is a diagonal matrix of size M x M to weight each equation.
, containing the changes in hypocentral parameters we wish to determine, and W is a diagonal matrix of size M x M to weight each equation.
The solution of the double-difference system as defined in (3) is the set of hypocenters changes (latitude, longitude, depth and time) that minimizes the double-difference. That is, each event absolute location is moved so that its relative position with respect to the other events minimizes the difference between the observed and the calculated differential times.
This solution is achieved through an iterative process. An initial double-difference system is built and solved starting from the catalog event locations. The hypocenters are then updated based on the inversion solution, and the process repeats—building a new system and solving it again. This is repeated until a configured number of iterations is reached, usually between 10 and 20. At each iteration, the solver down-weights equations according to their residuals, following the dynamic weighting scheme described by Waldhauser & Ellsworth (2000). The a priori weights can also be configured to give higher priority to cross-correlated differential times or to account for pick uncertainties. Unlike the original method described in the paper, rtDD does not down-weight equations by inter-event distance, as the residual-based re-weighting naturally accounts for the increased errors typically associated with more distant event pairs.
The double-difference system is solved using a least-squares approach. rtDD supports both the LSQR (Paige & Saunders, 1982) and LSMR (Fong & Saunders, 2011) algorithms, which are highly efficient for large, sparse linear systems. rtDD does not offer Singular Value Decomposition (SVD), as its computational complexity makes it impractical for large datasets.
In order to compute the partial derivatives and the calculated differential travel times, a velocity model is required. To avoid the run time computational costs of ray tracing during the inversion, rtDD is designed to support precomputed travel time tables (including velocity at source and take-off angle). See Custom Velocity Models.
Solving for both Absolute and Relative Locations
While absolute location methods seek the position that best explains absolute arrival times, double-difference methods focus on the relative configuration that best explains the timing differences between pairs. Because the focus is on differential time, the inversion can be susceptible to a cluster centroid shift: the internal structure of a cluster improves, but the entire cluster may shift away from its true absolute location.
To mitigate this, Waldhauser & Ellsworth (2000) suggest two approaches. The first is to add four additional equations - one for each coordinate direction and one for origin time - to constrain the mean shift of the cluster to zero. This is common in SVD-based solvers. For least-squares solvers like those used in rtDD, the second approach is preferred: regularization via a damped least-squares method. A damping factor ( ) forces the solver to minimize both the double-difference residuals and the changes to the hypocenters, preventing large, unconstrained shifts in absolute location. This damping also improves the numerical stability of ill-conditioned systems. The result is a relocation where the cluster centroid remains near its original average location while its internal structure (relative locations) is refined.
) forces the solver to minimize both the double-difference residuals and the changes to the hypocenters, preventing large, unconstrained shifts in absolute location. This damping also improves the numerical stability of ill-conditioned systems. The result is a relocation where the cluster centroid remains near its original average location while its internal structure (relative locations) is refined.
rtDD implements this damped least-squares approach. The double-difference system (3), with the inclusion of the damping factor and the identity matrix I, of size 4N x 4N - with N being the number of events, then becomes:
(4)
Finding the optimal is often an empirical process:
Low damping: Allows for pure relative refinement but risks large cluster shifts.
High damping: Prevents the events from moving significantly.
Optimal damping: A broad range of values where relative locations improve while the overall travel time RMS remains stable compared to the initial catalog.
Inclusion of Absolute Travel-Time Residuals
rtDD offers an advanced option to incorporate both absolute and relative constraints into a single inversion. This approach positions the cluster at an absolute location that minimizes total travel time residuals while simultaneously refining internal relative locations.
This method recognizes that absolute travel time residuals are known during inversion and can be constrained. For every phase k of every event e, we can add an equation that forces the hypocenters change, computed to minimize the double-differences, to match the absolute travel time residual:
(5)
With the inclusions of these equations the double-difference system (4) then becomes:
(6)
where K defines a matrix of size Z x 4N (Z, number of absolute travel time residuals; N, number of events) containing the partial derivatives, r is the vector of size Z containing the absolute travel time residuals and  is a scalar weight balancing the absolute and relative constraints.
is a scalar weight balancing the absolute and relative constraints.
In this system, the damping factor becomes less critical and can be set to a very low value. The weight is determined empirically:
Low
: Behaves like standard double-difference (relative refinement only).High
: Forces the solution toward the absolute locations, potentially sacrificing relative precision.Balanced
: Typically a broad range where both the double-difference residuals (cluster shape) and the absolute travel time RMS (cluster location) are improved.
In practice, this modified system ensures that clusters are shifted to locations that decrease the average RMS of all events while maintaining the high-precision relative structure provided by the double-difference method.
Evaluating the Results
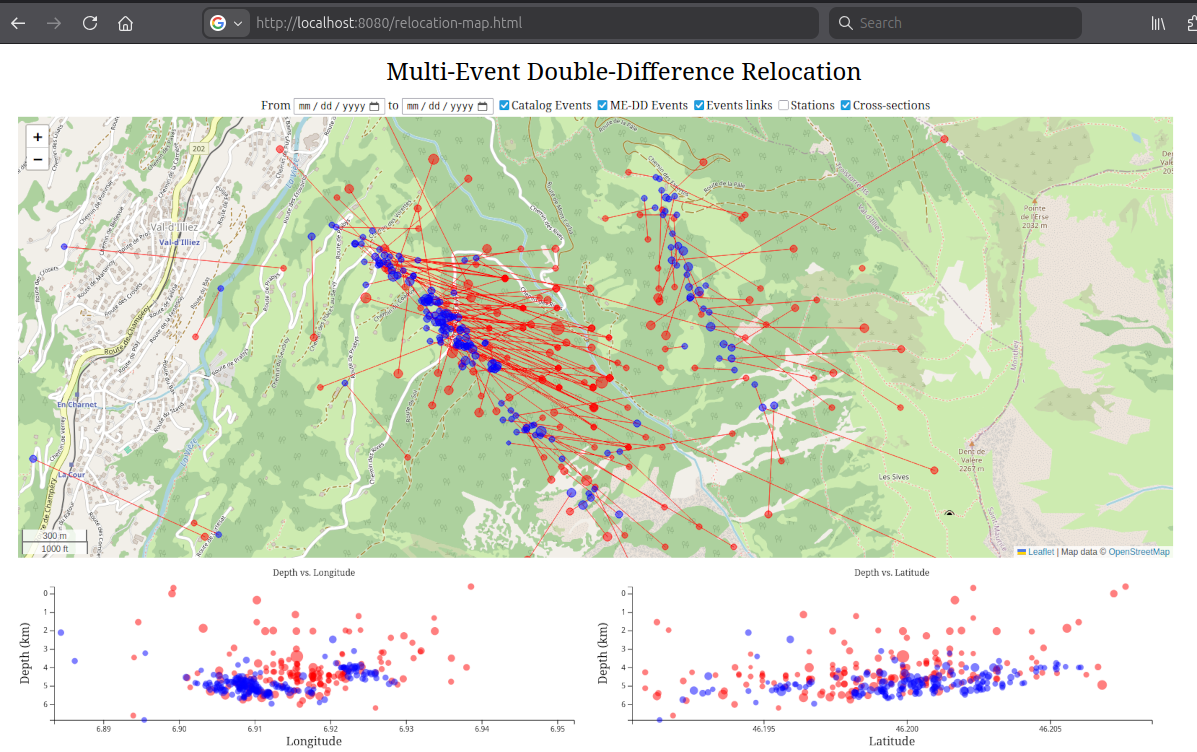
Visual Evaluation
For rapid visualization, use the relocation-map.html in this folder. It requires event.csv, station.csv, and reloc-event.csv to be in the same directory. You can view it by starting a local web server (e.g., python3 -m http.server 8080) and navigating to http://localhost:8080/relocation-map.html.
Quantitative Evaluation
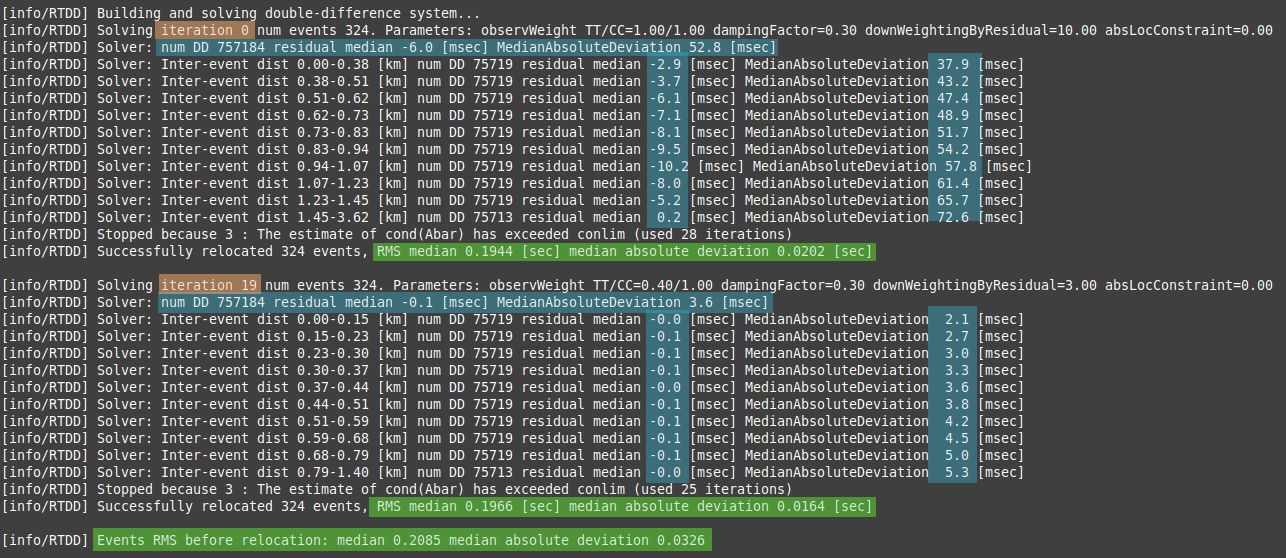
A successful relocation should decrease the double-difference residuals (improving relative locations) without increasing the absolute travel time RMS (stability in the absolute locations). These metrics are printed in the logs at each iteration, but a more granular analysis can be performed using specific columns of reloc-event.csv and reloc-phase.csv for absolute travel time residuals, and (if --dump-diagnostics is used) within a dedicated diagnostics folder (in particular initial/final-double-difference.csv) for double-difference residuals and cross-correlation results.
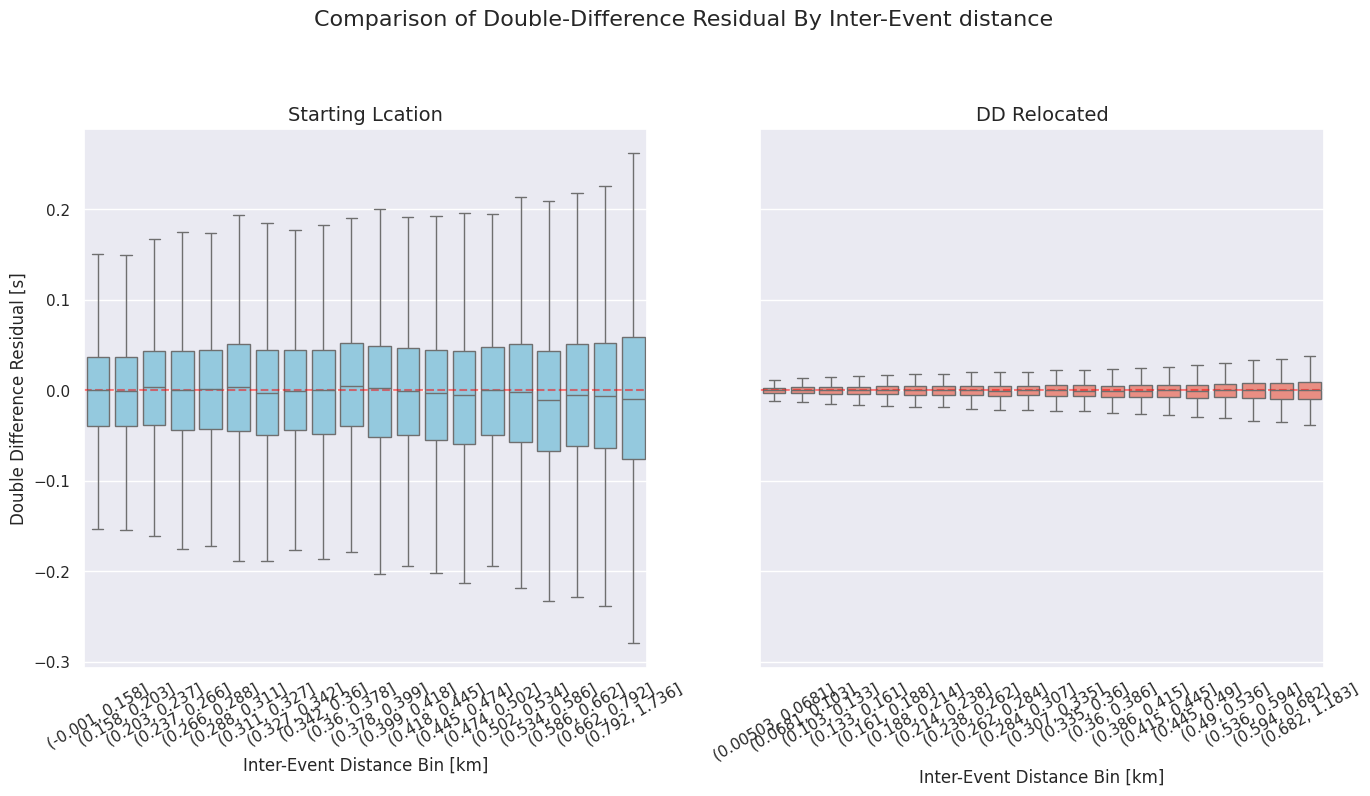
Verifying DD System Residuals and Absolute RMS
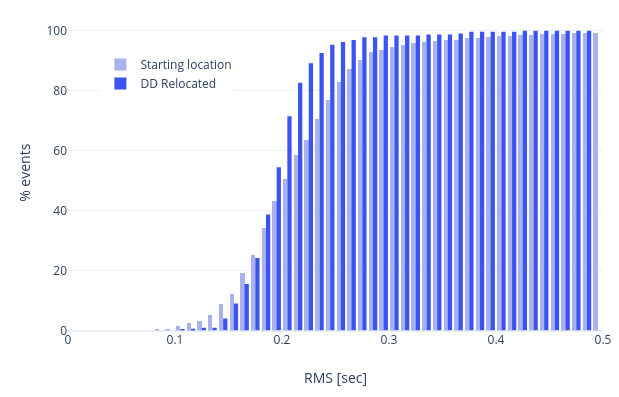
The logs show how double-difference residuals decrease over iterations and their relationship with inter-event distance. Stability or improvement in the absolute travel time RMS confirms that the cluster’s absolute position remains accurate.
Detailed diagnostics dumped via --dump-diagnostics provide details of the double-difference residuals in initial/final-double-difference.csv (see doubleDifferenceResidual column). You can use the scripts in this folder to plot them.
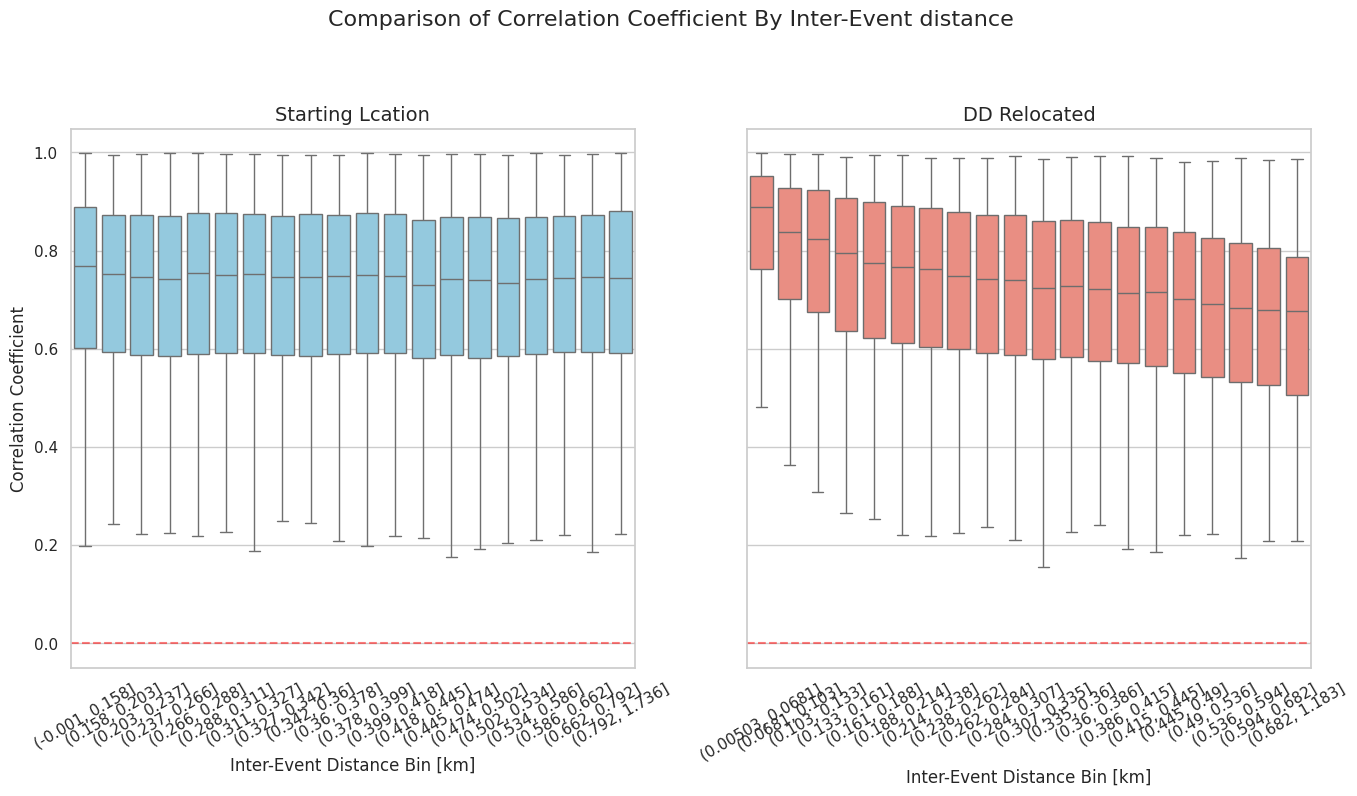
Verifying Relative Locations with Cross-Correlation
Waveform similarity is a strong indicator of proximity. Comparing correlation coefficients by inter-event distance before and after relocation provides an independent verification of the new relative locations.
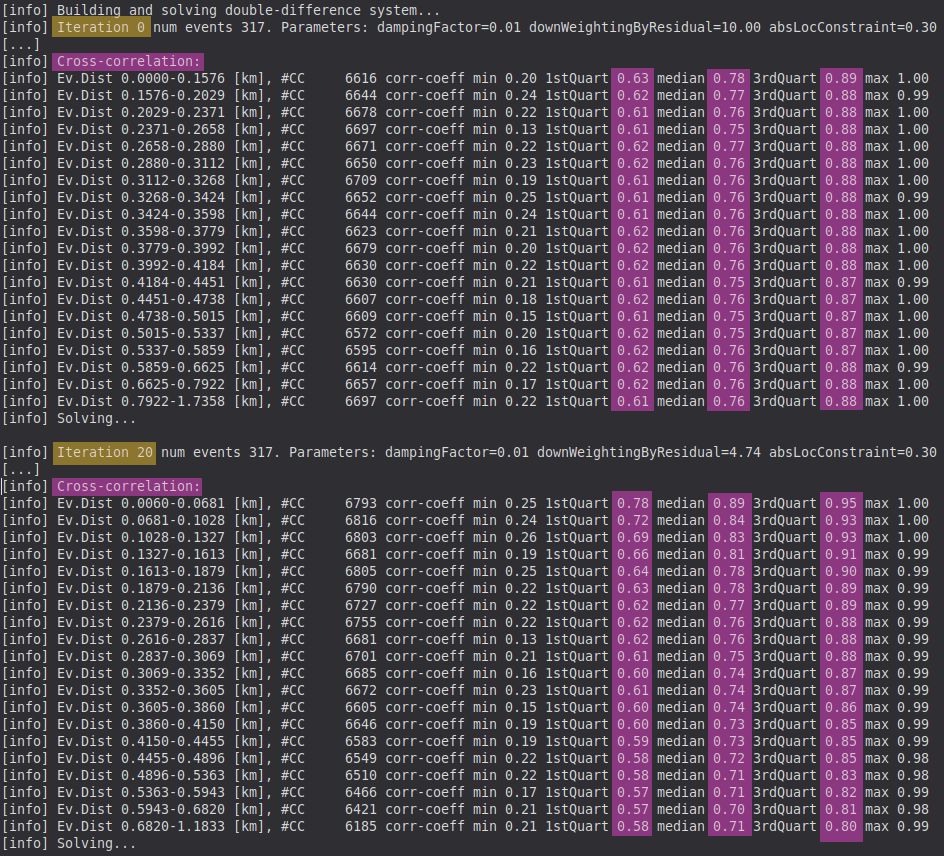
Detailed diagnostics dumped via --dump-diagnostics provide details of the cross-correlation results in initial/final-double-difference.csv (xcorrCoefficient column). You can use the scripts in this folder to plot them.
Verifying Absolute Locations
rtDD calculates the RMS both before and after (columns startRms and finalRms in reloc-event.csv) relocation using its own travel time engine. This provides a consistent baseline for comparison, as different locators may use different weighting schemes or travel time tables that make their RMS values incomparable. You can use the scripts in this folder to plot them.