dlpick¶
Phase detection and picking on waveforms.
Description¶
dlpick is a highly configurable SeisComP StreamApplication client that reads waveforms from recordstream and outputs picks, processed by Deep Learning (DL) models, that were created and trained using the SeisBench framework.
Installation¶
Install dlpick using gsm:
$ gsm install dlpick
This installs three packages:
dlpick - this application
dlbase - dependency package for deep learning applications
dlmodels-pick - DL models, installed to /home/data/dlmodels, by default
Workflow¶
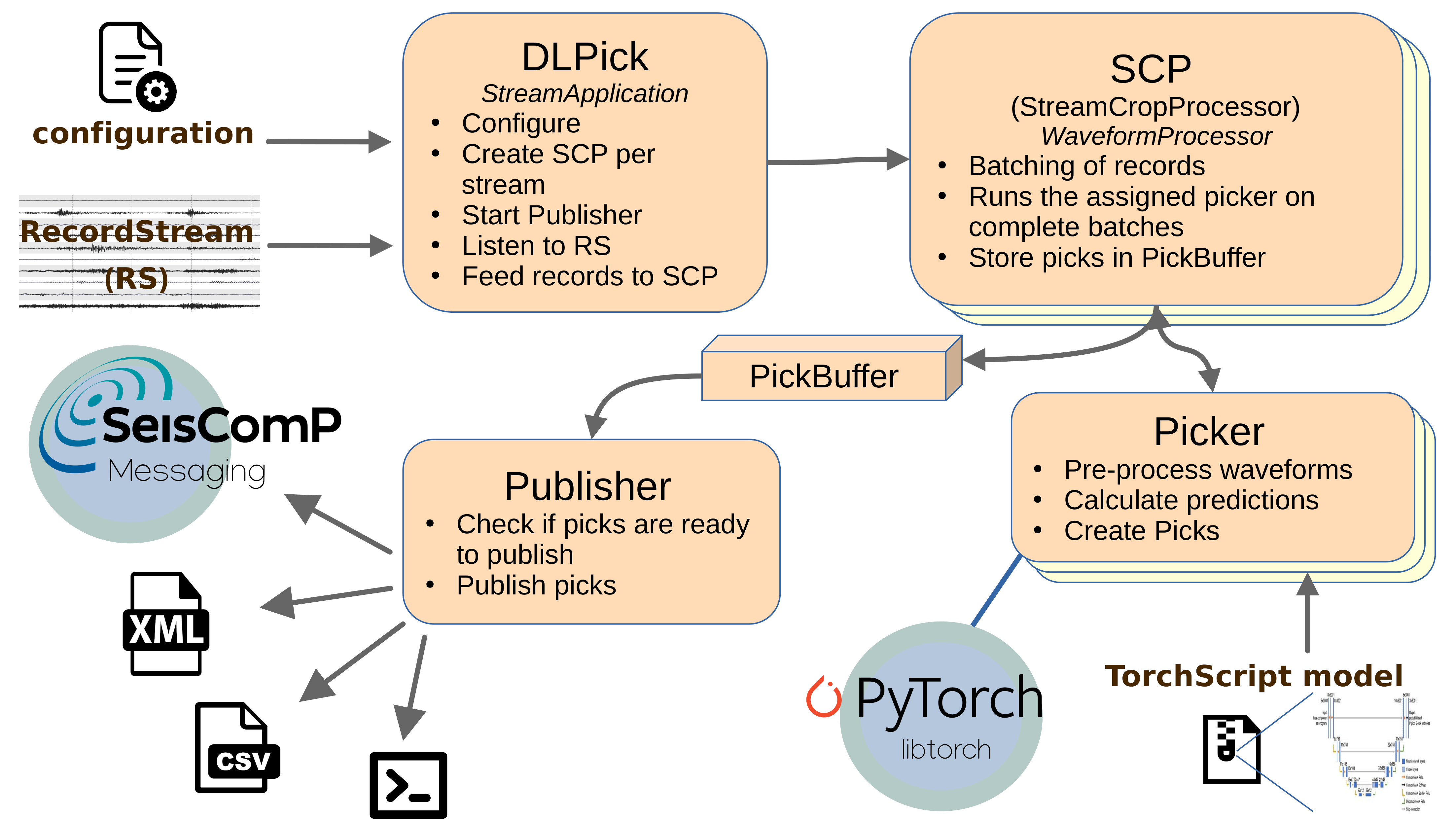
Figure 1: simplified architecture of dlpick¶
Use cases¶
Like any other SeisComP StreamApplication client, dlpick can read from any RecordStream, attach to a database and messaging. This also means, dlpick can operate in real-time and non-real-time mode, respectively. There is a module configuration for dlpick and you can also override most of the parameters using dlpick binding profiles for your stations.
Real-time mode¶
Make sure to have the necessary seiscomp modules running. For example, if you provide waveforms via seedlink:
$ seiscomp start scmaster seedlink
While it is possible to start dlpick as a module like above (or via scconfig), we will have a look at the commandline, first:
Without any arguments, dlpick will use the local configuration, connect to the local database and messaging.
$ dlpick
If you already have global bindings attached to your streams providing detecStream and detecLocid, dlpick will use its default settings to process streams and send resulting picks to the messaging. One major difference to scautpick is that, in general, DL models need three components. Therefore dlpick will try to find three-component channels based on the parameters above.
The DL model¶
The default DL model is PhaseNet with its original weights. This model needs 30s input of raw three-component data with sample rate of 100 sps. The app takes care of resampling and all pre-processing steps that are specific to the model.
Other models can be used, currently only EQTransformer and PhaseNet architectures are supported. A list of available models, that shipped with your installation:
$ dlpick --print-models
Hint
For details on models and the data that they were trained on, take a look into the SeisBench docs. There you will find most of the datasets that were printed with –print-models in parentheses. Those models without further description were trained by gempa on specific datasets. A detailed description of these models is still not available. But feel free to try them out.
Try another model. For local seismicity, “instance” weights are a good choice.
$ dlpick --model-weights eqtransformer-instance
Hint
Note that the model and the weights should be written in lower-case. It’s possible to use abbreviations for the weights,
as well. You could also type --model-weights eq-in.
In contrast to PhaseNet, the EQTransformer architecture needs 60s of input data.
In the configuration, use the parameter modelWeights.
It’s also available as a binding parameter.
Confidence thresholds¶
The applied DL model outputs data that can be considered as the model’s confidence about a P or an S pick for each data sample. This enables us to use confidence thresholds to restrict or relax the number (and quality) of picks. Default thresholds are very low 0.1. For most models and data, a threshold about 0.3 would be appropriate, for P and S respectively.
$ dlpick --p-threshold 0.3 --s-threshold 0.3
In the module configuration, you can set the P and the S thresholds per model type:
models.eqtransformer.PThresholdmodels.eqtransformer.SThresholdmodels.phasenet.PThresholdmodels.phasenet.SThreshold
They will act as a default for your model type. You can specify the thresholds in the bindings using
PThreshold and SThreshold.
Overlapping¶
It is advisable to process waveforms with overlapping time windows. This way the model gets more chances to find phase onsets that are close to the window’s borders. But this also means more picks. dlpick uses a reduction algorithm that searches for very dense picks and selects only those with the highest confidence.
To set a useful overlapping (between 0.5 and 0.9), but keep in mind that this comes at the expense of performance:
$ dlpick --ol-ratio 0.9
Per default, the reduction algorithm ensures picks have a distance of at least 5s to each other. If you think this interval is too wide, you can change it (currently for the corresponding model architecture only), say to 1.9s:
$ dlpick --model-weights eqtransformer-in --ol-ratio 0.9 --models.eqtransformer.reducePicksInterval=1.9
In the module configuration, you can set the overlapping ratio per model type:
models.eqtransformer.traceWindowOlRatiomodels.phasenet.traceWindowOlRatio
They will act as a default for your model type. You can specify the thresholds in the bindings using
traceWindowOlRatio.
The interval for the pick reduction algorithm can be set, as mentioned above, only per model type:
models.eqtransformer.reducePicksIntervalmodels.phasenet.reducePicksInterval
Hint
These options are planned to exist as well as binding parameters, in a future release.
Performance¶
Batches¶
To improve performance, waveforms should be processed in a batch and, if possible on the GPU. Per default, the batch size is already 32. But this might lead to longer waiting times. If you experience this as a problem, set the batch-size to 1, to process each data window, instantly:
$ dlpick --batch-size 1
Batches are packed for each Picker configuration. This means, if multiple streams are processed with the same configuration, only one Picker is in charge. Each picker will try to fill a batch of the same size before processing the data.
Hint
This behavior is very likely to change in future releases, as it can be desirable to have one picker for many streams running with large batch size and another one for, e.g., only one station, where picks data processing would be delayed if the batch size were to large.
If you don’t use bindings, there will be one Picker configuration only and the batch size will apply to all processed data.
In the module configuration and in the bindings, the parameter is called batchSize.
GPU¶
If your machine has a CUDA GPU, you should use it to accelerate predictions, together with appropriate batch sizes:
$ dlpick --gpu --batch-size 128
However, this will be more of advantage in offline mode.
You will find the parameter gpu in the module configuration but not as a binding parameter.
Phase hints¶
Per default, dlpick puts a ‘d’ in front of the phase name and appends the confidence as percentage:
"dP (93.3%)", "dS (10.1%)"
If you need clean phaseHints for your pipeline, change that like this:
$ dlpick --phase-prefix "" --phase-postfix ""
The corresponding module configuration parameters are: phasePrefix and phasePostfix.
Output¶
If you don’t want to send the picks to the messaging, there are other ways, look at these options:
Write to SCML file:
--epWrite CSV file:
--csvPrint to terminal:
--stdout
These options don’t take arguments (file names are numbered but will always have the same name stem) and they can be combined.
Note
If one of these parameters is provided, “sending to message” will be deactivated. The same applies if you set the same-named parameters in the module configuration.
To activate “sending to messaging”, on the commandline:
$ dlpick -H localhost
Parameters ep, csv and stdout can be used in the module configuration.
Example: offline playback¶
Of course, dlpick can process miniSEED files and work in offline / playback mode completely:
$ dlpick -I waveforms.mseed --inventory-db inventory.xml --config-db config.xml --config-file dlpick.cfg \
--ep --offline --batch-size 512 --gpu --stdout --out /tmp
Concepts¶
Reduction algorithm¶
With the overlapping of prediction windows, picks of two overlapping windows might refer to the same onset.
Simple Reduction Algorithm¶
Whether two picks define the same phase onset, is currently controlled by an interval for the simple reduction algorithm. This means if two picks lie in the same interval, they will be merged and only the more confident one “survives”. The simple reduction algorithm iterates through the ordered list of picks (one direction: from past to future) and looks ahead for the interval time. The next found pick will be merged with the first one, and so on. The algorithm will be applied a second time, because the merged pick will be skipped in the first run for the next comparison, thus, it could be too dense to a neighboring pick no matter if the latter was merged as well. This two-passes strategy tickles the issue of progressively moving picks: Let’s say a bunch picks lie very close to each other with increasing confidence, but the first and the second halves of picks refer to actually different onsets. If we would use a one-pass strategy and use the last merged pick as starting point for the next comparison then we could end up in a situation where no pick for the first event is left.
Pick Cluster Reduction Algorithm¶
Instead of linearly merging picks, this algorithm clusters close picks based on given distance. The algorithm works in 4 steps: 1. For each pick a cluster is formed adding all neighboring picks that are close enough. 2. Each pick is assigned to the nearest cluster based on central distance. The created clusters can overlap. 3. Merge all overlapping clusters 4. Check all clusters that are either before the “safe-time” or whose number of picks exceed the given threshold.
Module Configuration¶
etc/defaults/global.cfgetc/defaults/dlpick.cfgetc/global.cfgetc/dlpick.cfg~/.seiscomp/global.cfg~/.seiscomp/dlpick.cfgdlpick inherits global options.
Note
Modules/plugins may require a license file. The default path to license
files is @DATADIR@/licenses/ which can be overridden by global
configuration of the parameter gempa.licensePath. Example:
gempa.licensePath = @CONFIGDIR@/licenses
- before¶
Default:
300Unit: s
Type: int
Defines the time in seconds to start picking on waveforms before current time.
- modelsPath¶
Default:
/home/data/dlmodels/dlmodels-pickType: path
Search path for Deep Learning models. This path is also used to look up the file "dlmodels_maps.json" holding additional information on the available models.
- modelWeights¶
Type: string
Full name of model to load. The string must be the same as the file name stem of the model. It is also possible to use the seisbench naming convention by separating model and weights string with a dash. Normally, both should be abbreviations for the actual names, but lowercase full names or aliases are possible as well. E.g. "pn-in", "phasenet-in", "pn-instance", as well as "phasenet-instance" will all load the same PhaseNet model.
- phasePrefix¶
Default:
dType: string
Prefix that will be put in front of the phase hint.
- phasePostfix¶
Type: string
Suffix for the phaseHint string of the pick. This string is interpolated like a Python format string. You can use "$c" as placeholder for the pick confidence. Example: "({$c:.1%})" would result in "(56.0%)" as a suffix for a pick with confidence 0.56012345, whereas "{$c}" would simply add the confidence to the phase string: "0.56012345". Note that "$c" needs to be inside a curly-brace context to work as a variable.
- phaseMap¶
Type: string
Rename phase hints. E.g., to rename P to Is and S to It: "P:Is,S:It"
- ep¶
Type: boolean
If set, picks will be dumped to an XML file. Can be combined with --csv. You can change the output path using parameter
outDiror --out on the commandline. During a run, dlpick generates consecutively numbered files with the file name stem "picks". When the picker is about to finish, those files are merged into one big file with the stem named "picks-merged". If one or more files with the same name already exist, dlpick will also number the file name.
- csv¶
Type: boolean
If set, picks will be dumped to csv file. Can be combined with --ep. You can change the output path using parameter
outDiror --out on the commandline. For more details see option --ep.
- stdout¶
Type: boolean
If set, picks will be dumped to stdout in the form of "streamID phaseHint : time confidence: confidenceValue model weights".
- gpu¶
Type: boolean
If set, model and data will work on the GPU if cuda is available on the machine else on CPU.
- traceWindowOlRatio¶
Default:
0.0Type: double
Ratio defining how much trace windows are overlapping each other.
- batchSize¶
Type: int
Number of data windows to process per picker at the same time.
- minPrefDataRatio¶
Default:
1.33Type: double
(Surplus) ratio of data in relation to the actually necessary (model-defined) length that the app shall wait for before passing the data to the inference step. Having surplus data allows finding component overlaps without padding missing data with zeros.
- maxGap¶
Default:
0.5Unit: s
Type: double
(Not implemented!) Maximum gap in seconds that is tolerated for records to be considered as continuous. Note that the gap will be linearly interpolated.
- snrThreshold¶
Type: double
A pick whose SNR is up to this threshold won’t be published. Won’t be applied if set to 0.
- outDir¶
Type: string
Set output folder for pick xml/csv files.
- filter¶
Type: string
The filter to apply on the data before it is sent to the picker. This parameter overrides any model or station filter parameter.
- minGatherPicksBeforeReduce¶
Default:
10Type: int
This parameter sets the number of picks that must be staged before the reduction algorithm is applied to them.
Details: Minimum-size criterion for applying the reduction algorithm to a pick buffer. When pushing to or popping from a pick buffer, this criterion is tested as well as the timeout. If one of them is true, the reduction will be applied. (There is a pick buffer for each stream.)
- minTimeBeforeReduce¶
Default:
10.0Unit: s
Type: double
This parameter sets the timeout for staging picks until the reduction algorithm is applied to them. After reduction, the timer starts over again.
Details: Timeout criterion for applying the reduction algorithm to a pick buffer. When pushing to or popping from a pick buffer, this criterion is tested as well as the minimum picks number. If one of them is true, the reduction will be applied. (There is a pick buffer for each stream.)
- minGatherPicksBeforeFlush¶
Default:
10Type: int
This parameter sets the number of picks that must be gathered before publishing.
Details: Minimum-size criterion for flushing a pick buffer. When the publisher process tries to pop picks from the pick buffers, this criterion is tested as well as the timeout. If one of them is true, those picks considered as safe-to-flush will be sent to the output sinks.
- minTimeBeforeFlush¶
Default:
10.0Unit: s
Type: double
This parameter sets the timeout for gathering picks until they are published. After publishing, the timer starts over again with the next staging of picks, in a buffer.
Details: Time criterion for flushing a pick buffer. When the publisher process tries to pop picks from the pick buffers, this criterion is tested as well as the minimum picks number. If one of them is true, those picks considered as safe-to-flush will be sent to the output sinks.
- PThreshold¶
Default:
0.1Type: double
Threshold defining the minimum confidence of for a P pick.
- SThreshold¶
Default:
0.1Type: double
Threshold defining the minimum confidence of for an S pick.
- uncertainPThresh¶
Type: double
If set, adds additional picks with a lower threshold, marking them with the prefix ‘u’. Picks above the normal
PThresholdare not touched. This value can be overridden by the same-named bindings’ config parameter for the corresponding set of stations.
- uncertainSThresh¶
Type: double
If set, adds additional picks with a lower threshold, marking them with the prefix ‘u’. Picks above the normal
SThresholdare not touched. This value can be overridden by the same-named bindings’ config parameter for the corresponding set of stations.
- picksReductionAlgorithm¶
Default:
ClusterType: string
Values:
Cluster,SimpleThe picks reduction algorithm to use.
Choose "Simple" for the "Simple Reduction" algorithm. This one is applied at some point on staged picks and reduces too dense picks in a linear fashion.
Choose "Cluster" for the "Cluster Reduction" algorithm. This one is applied at some point on the staged picks. Picks in "safe" clusters lying before the "safe time" (i.e., when no more new picks are expected to join the cluster) are reduced instantly, while the others remain "staged". This algorithm allows the option safeReduceMinPickCount to define a threshold of pick count for a cluster to be reduced even before the "safe time" criterion hits.
- reducePicksInterval¶
Default:
5.0Unit: s
Type: double
(DEPRECATED) Sets the time span in seconds before and after a pick where no other pick is supposed to exist.
The algorithm leaves only those picks with the highest confidence in the interval.
- blindingSamples¶
Default:
0Type: ints
Count of samples at the start and in the end of a model’s prediction to ignore. DLPick won’t try to look for picks in these edge regions. Value is intended to be a pair of integers for start and end region, but when setting a single number, the same value will be applied for start and end regions.
Bindings Parameters¶
- streamChannels¶
Type: string
A list of channels as input for the picker model. Overrides global.detecStream. The order of channels is determined by the model’s "component_order" parameter. Therefore, the last letters must be distinct. E.g., ‘EHZ,HDF’. ‘BH’ would tell the model to try to log all three components (i.e.,BHZ, BHN, BHE), exactly as
global.detecStreamwould do. You can further define that a channel can be neglected if no data is available by annotating it with a ‘:0’, e.g., ‘HDF:1,EHZ:0’. Another feature is the possibility to force a specific location code, even though it might not be found in the inventory: ‘DN.EHZ:1,HDF:1’. This can be useful if the record stream provides processed data via a fake location ‘DN’.
- modelWeights¶
Type: string
Name of the picker model to use. See module config for details.
- traceWindowOlRatio¶
Type: double
Ratio defining how much trace windows are overlapping each other.
- batchSize¶
Type: int
Number of data windows to process per picker at the same time.
- PThreshold¶
Type: double
Set the confidence threshold for P picks.
This value overrides the same-named config parameter of the chosen model type for the corresponding set of station(s).
- SThreshold¶
Type: double
Set the confidence threshold for S picks.
This value overrides the same-named config parameter of the chosen model type for the corresponding set of station(s).
- blindingSamples¶
Type: ints
Count of samples at the start and in the end of a model’s prediction to ignore. DLPick won’t try to look for picks in these edge regions. Value is intended to be a pair of integers for start and end region, but when setting a single number, the same value will be applied for start and end regions.
- uncertainPThresh¶
Type: double
If set, adds additional picks with a lower threshold, marking them with the prefix ‘u’. Picks above the normal
PThresholdare not touched.This value overrides the same-named global config parameter for the corresponding set of stations.
- uncertainSThresh¶
Type: double
If set, adds additional picks with a lower threshold, marking them with the prefix ‘u’. Picks above the normal
SThresholdare not touched.This value overrides the same-named global config parameter for the corresponding set of stations.
- minPrefDataRatio¶
Type: double
(Surplus) ratio of data in relation to the actually necessary (model-defined) length that the app shall wait for before passing the data to the inference step. Having surplus data allows finding component overlaps without padding missing data with zeros.
This value overrides the same-named config parameter of the chosen model type for the corresponding set of station(s).
- phaseToComp¶
Type: string
Map a pick to a component. E.g., ‘P:Z,S:Z’ would output both P and S on the Z component. Make sure that the station of this binding actually has the corresponding component.
If not set, per default, dlpick puts P picks on the vertical and S picks on the first horizontal component.
- maxGap¶
Unit: s
Type: double
(Not implemented!) Maximum gap in seconds that is tolerated for records to be considered as continuous. Note that the gap will be linearly interpolated.
- snrThreshold¶
Type: double
A pick whose SNR is up to this threshold won’t be published. Won’t be applied if set to 0.
- filter¶
Type: string
The filter to apply on the data before it is sent to the picker.
- picksReductionAlgorithm¶
Default:
ClusterType: string
Values:
Cluster,SimpleThe picks reduction algorithm to use.
Choose "Simple" for the "Simple Reduction" algorithm. This one is applied at some point on staged picks and reduces too dense picks in a linear fashion.
Choose "Cluster" for the "Cluster Reduction" algorithm. This one is applied at some point on the staged picks. Picks in "safe" clusters lying before the "safe time" (i.e., when no more new picks are expected to join the cluster) are reduced instantly, while the others remain "staged". This algorithm allows the option safeReduceMinPickCount to define a threshold of pick count for a cluster to be reduced even before the "safe time" criterion hits.
- safeReduceMinPickCount¶
Type: int
This parameter is only used by the cluster algorithm for pick reduction.
If a cluster contains at least safeReduceMinPickCount number of picks, they will be reduced to one, which will be emitted early. The interval will be stored and any picks later on lying within it will be ignored. Apart from this specific behavior, picks are being reduced when all potential clusters are filled by predictions, and no more picks can be expected by future predictions because the next prediction window would start after the cluster’s end.
- picksReductionClusterSize¶
Default:
1.0Unit: s
Type: double
Control the maximum length of a pick cluster.
If the "Cluster" algorithm was chosen in parameter picksReductionAlgorithm then clusters of dense picks with a maximum extent of picksReductionClusterSize seconds will eventually be reduced to the most confident pick in this cluster.
- picksReductionSimpleInterval¶
Default:
1.0Unit: s
Type: double
Control the interval for the "Simple" picks reduction algorithm.
If the "Simple" algorithm was chosen in parameter picksReductionAlgorithm, this parameter sets the time span in seconds before and after a pick where no other pick is supposed to exist.
The algorithm leaves only those picks with the highest confidence in the interval after each reduction run.
- minGatherPicksBeforeReduce¶
Default:
10Type: int
This parameter sets the number of picks that must be staged before the reduction algorithm is applied to them.
Details: Minimum-size criterion for applying the reduction algorithm to a pick buffer. When pushing to or popping from a pick buffer, this criterion is tested as well as the timeout. If one of them is true, the reduction will be applied. (There is a pick buffer for each stream.)
This value overrides the same-named global config parameter for the corresponding set of stations.
- minTimeBeforeReduce¶
Default:
10.0Unit: s
Type: double
This parameter sets the timeout for staging picks until the reduction algorithm is applied to them. After reduction, the timer starts over again.
Details: Timeout criterion for applying the reduction algorithm to a pick buffer. When pushing to or popping from a pick buffer, this criterion is tested as well as the minimum picks number. If one of them is true, the reduction will be applied. (There is a pick buffer for each stream.)
This value overrides the same-named global config parameter for the corresponding set of stations.
- minGatherPicksBeforeFlush¶
Default:
10Type: int
This parameter sets the number of picks that must be gathered before publishing.
Details: Minimum-size criterion for flushing a pick buffer. When the publisher process tries to pop picks from the pick buffers, this criterion is tested as well as the timeout. If one of them is true, those picks considered as safe-to-flush will be sent to the output sinks.
This value overrides the same-named global config parameter for the corresponding set of stations.
- minTimeBeforeFlush¶
Default:
10.0Unit: s
Type: double
This parameter sets the timeout for gathering picks until they are published. After publishing, the timer starts over again with the next staging of picks, in a buffer.
Details: Time criterion for flushing a pick buffer. When the publisher process tries to pop picks from the pick buffers, this criterion is tested as well as the minimum picks number. If one of them is true, those picks considered as safe-to-flush will be sent to the output sinks.
This value overrides the same-named global config parameter for the corresponding set of stations.
Command-Line Options¶
dlpick [options]
Generic¶
- -h, --help¶
Show help message.
- -V, --version¶
Show version information.
- --config-file file¶
The alternative module configuration file. When this option is used, the module configuration is only read from the given file and no other configuration stage is considered. Therefore, all configuration including the definition of plugins must be contained in that file or given along with other command-line options such as --plugins.
- --plugins arg¶
Load given plugins.
- -D, --daemon¶
Run as daemon. This means the application will fork itself and doesn’t need to be started with &.
- --auto-shutdown arg¶
Enable/disable self-shutdown because a master module shutdown. This only works when messaging is enabled and the master module sends a shutdown message (enabled with --start-stop-msg for the master module).
- --shutdown-master-module arg¶
Set the name of the master-module used for auto-shutdown. This is the application name of the module actually started. If symlinks are used, then it is the name of the symlinked application.
- --shutdown-master-username arg¶
Set the name of the master-username of the messaging used for auto-shutdown. If "shutdown-master-module" is given as well, this parameter is ignored.
- --print-models¶
Print list of available models.
Verbosity¶
- --verbosity arg¶
Verbosity level [0..4]. 0:quiet, 1:error, 2:warning, 3:info, 4:debug.
- -v, --v¶
Increase verbosity level (may be repeated, e.g., -vv).
- -q, --quiet¶
Quiet mode: no logging output.
- --component arg¶
Limit the logging to a certain component. This option can be given more than once.
- -s, --syslog¶
Use syslog logging backend. The output usually goes to /var/lib/messages.
- -l, --lockfile arg¶
Path to lock file.
- --console arg¶
Send log output to stdout.
- --debug¶
Execute in debug mode. Equivalent to --verbosity=4 --console=1 .
- --log-file arg¶
Use alternative log file.
Messaging¶
- -u, --user arg¶
Overrides configuration parameter
connection.username.
- -H, --host arg¶
Overrides configuration parameter
connection.server.
- -t, --timeout arg¶
Overrides configuration parameter
connection.timeout.
- -g, --primary-group arg¶
Overrides configuration parameter
connection.primaryGroup.
- -S, --subscribe-group arg¶
A group to subscribe to. This option can be given more than once.
- --content-type arg¶
Overrides configuration parameter
connection.contentType.Default:
binary
- --start-stop-msg arg¶
Default:
0Set sending of a start and a stop message.
Database¶
- --db-driver-list¶
List all supported database drivers.
- -d, --database arg¶
The database connection string, format: service://user:pwd@host/database. "service" is the name of the database driver which can be queried with "--db-driver-list".
- --config-module arg¶
The config module to use.
- --inventory-db arg¶
Load the inventory from the given database or file, format: [service://]location .
Records¶
- --record-driver-list¶
List all supported record stream drivers.
- -I, --record-url arg¶
The RecordStream source URL. Format: [service://]location[#type]. "service" is the name of the RecordStream driver which can be queried with "--record-driver-list". If "service" is not given, "file://" is used and simply the name of a miniSEED file can be given.
- --record-file arg¶
Specify a file as record source.
- --record-type arg¶
Specify a type for the records being read.
Output¶
- --phase-prefix¶
Overrides configuration parameter
phasePrefix.
- --phase-postfix¶
Overrides configuration parameter
phasePostfix.
- --no-file-merging¶
This option prevents that, when the application finishes, all output files are merged into one, which it does per default.
Picking¶
- --model-weights¶
Overrides configuration parameter
modelWeights.
- --ol-ratio¶
Overrides configuration parameter
traceWindowOlRatio.
- --p-threshold¶
Overrides configuration parameter
PThreshold.
- --s-threshold¶
Overrides configuration parameter
SThreshold.
- --p-uncertain¶
Overrides configuration parameter
uncertainPThresh.
- --s-uncertain¶
Overrides configuration parameter
uncertainSThresh.
- --snr-threshold¶
Overrides configuration parameter
models.eqtransformer.snrThreshold.
Mode¶
- --force-channels¶
Load stations by config but ignore channels specified in detecStream. Force loading streams with channels as listed. E.g., ‘HDF:1,EHZ:0’, where ‘1’ means ‘necessary’ and ‘0’ means ‘negligible’. In this example, if EHZ data is missing, zeros will be passed to the model, in its place. Attention: Since this parameter is global, use it only with a consistent model architecture.
- --offline¶
Do not connect to messaging server
- --ignore-bindings¶
Ignore station bindings read from config. Parameters from module configuration (overridden by commandline parameters) will be used for all stations.
- --prefer-bindings¶
Ignore options set by command line arguments, in case there is a specific station binding for the same parameter. This is useful when you want to test a certain value only on stations that have no bindings, but not on those with bindings, since they have their special settings for a good reason.